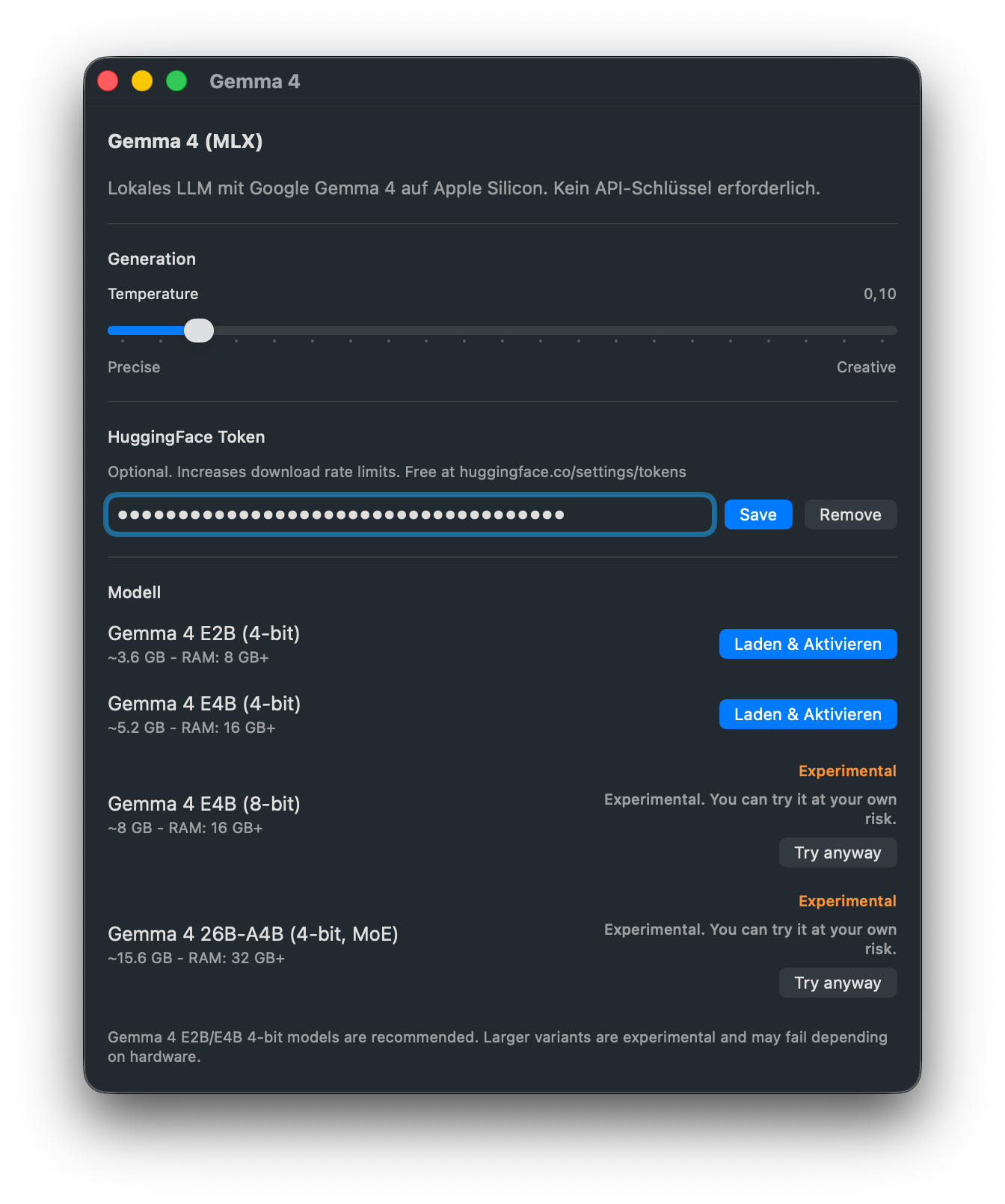
Gemma 4 bringt Googles Open-Weight-Modellfamilie Gemma als vollständig lokalen Anbieter für Prompt-Verarbeitung nach TypeWhisper auf Apple Silicon. Alles läuft direkt auf deinem Mac via MLX, sodass du Umschreibungen, Zusammenfassungen und eigene Prompt-Workflows ohne Cloud-Upload nutzen kannst. Im aktuell verifizierten Release-Pfad empfiehlt TypeWhisper ausdrücklich die dichten Varianten Gemma 4 E2B (4-bit) und Gemma 4 E4B (4-bit). Größere Varianten bleiben in der UI sichtbar, sind derzeit aber experimentell und können je nach Hardware oder Runtime-Unterstützung fehlschlagen.
Features
Vollständig lokale Prompt-Verarbeitung auf dem Gerät via MLX
Regler für die Generation Temperature zwischen präziser und kreativer Ausgabe
Optionaler HuggingFace-Token für höhere Download-Rate-Limits
Validierung des HuggingFace-Tokens vor dem Speichern
Download-, Lade-, Abbrechen- und Entladen-Zustände für lokale Modelle
Sichtbare experimentelle Modellvarianten mit klaren Warnhinweisen
Kein API-Key für den lokalen Basis-Workflow erforderlich
Verfügbare Modelle
Modell
Download-Größe
Empfohlener RAM
Status
Gemma 4 E2B (4-bit)
~3.6 GB
8 GB+
Empfohlen
Gemma 4 E4B (4-bit)
~5.2 GB
16 GB+
Empfohlen
Gemma 4 E4B (8-bit)
~8 GB
16 GB+
Experimentell
Gemma 4 26B-A4B (4-bit, MoE)
~15.6 GB
32 GB+
Experimentell
Konfiguration
Generation Temperature - Steuert, ob die Ausgabe eher präzise oder kreativer ausfällt.
HuggingFace Token - Optional. Erhöht Download-Rate-Limits und wird vor dem Speichern validiert. Du kannst ihn unter huggingface.co/settings/tokens erstellen.
Modell - Wähle, welche Gemma-4-Variante heruntergeladen und geladen werden soll. Die 4-bit-Modelle E2B und E4B sind aktuell der empfohlene Pfad.