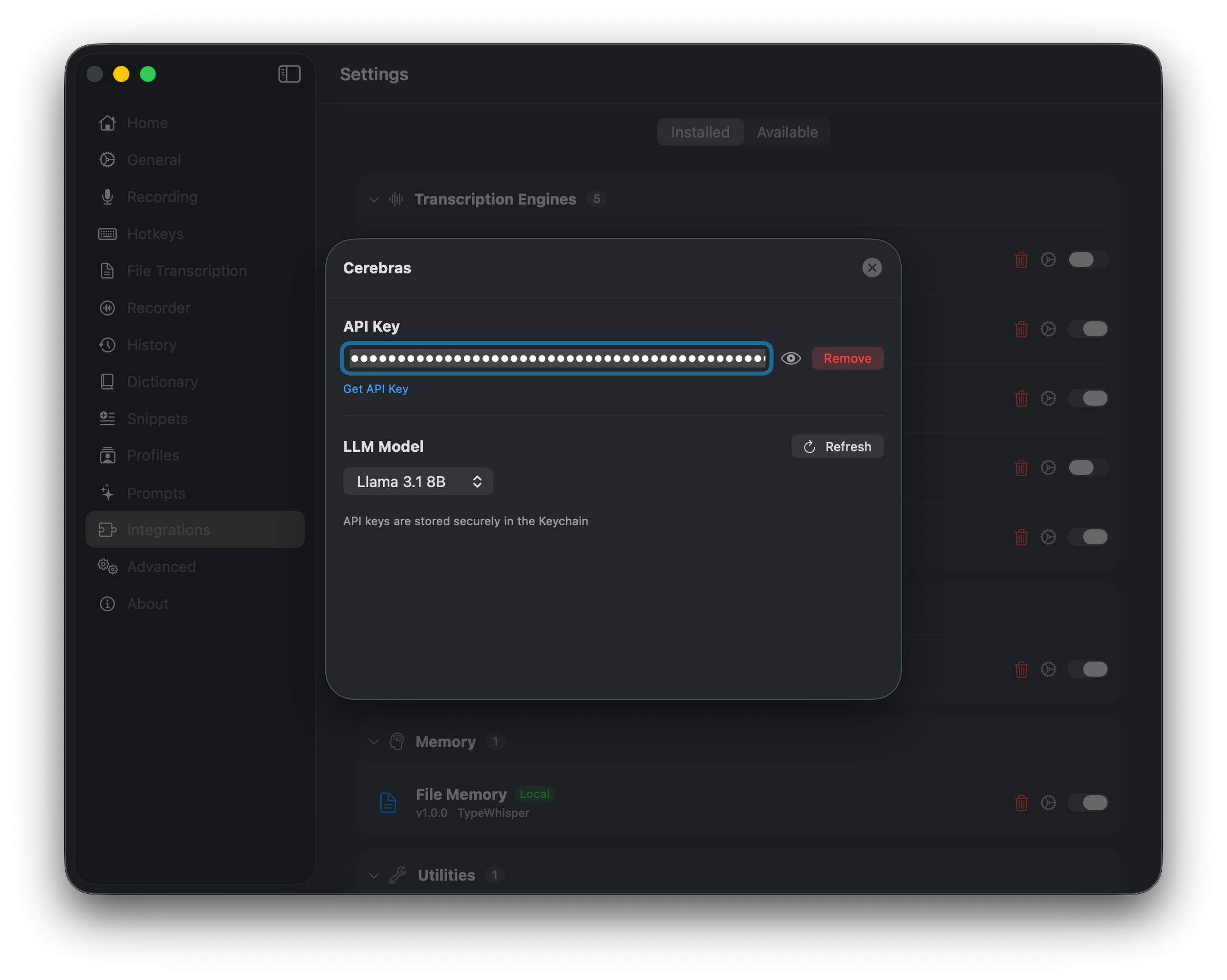
Cerebras delivers ultra-fast LLM inference using their custom Wafer-Scale Engine (WSE) hardware. The platform achieves speeds of around 3,000 tokens per second for large models like GPT-OSS 120B, making it one of the fastest cloud inference providers available. The plugin uses an OpenAI-compatible API and dynamically fetches available models.
Features
Ultra-fast inference (~3,000 tokens/sec for GPT-OSS 120B)
Dynamic model list with refresh from the Cerebras API
OpenAI-compatible API
API keys stored securely in the macOS Keychain
LLM Models
Model
ID
Llama 3.1 8B
llama3.1-8b
GPT-OSS 120B
gpt-oss-120b
Qwen 3 235B
qwen-3-235b-a22b-instruct-2507
ZAI GLM 4.7
zai-glm-4.7
Use the Refresh button to load the latest models from the Cerebras API.
Configuration
API Key - Sign up at cloud.cerebras.ai and generate an API key. Your key is stored securely in the macOS Keychain.
Setup
Open TypeWhisper Settings > Plugins
Find the Cerebras plugin and click Configure
Enter your Cerebras API key
Select an LLM model and choose Cerebras as your LLM provider