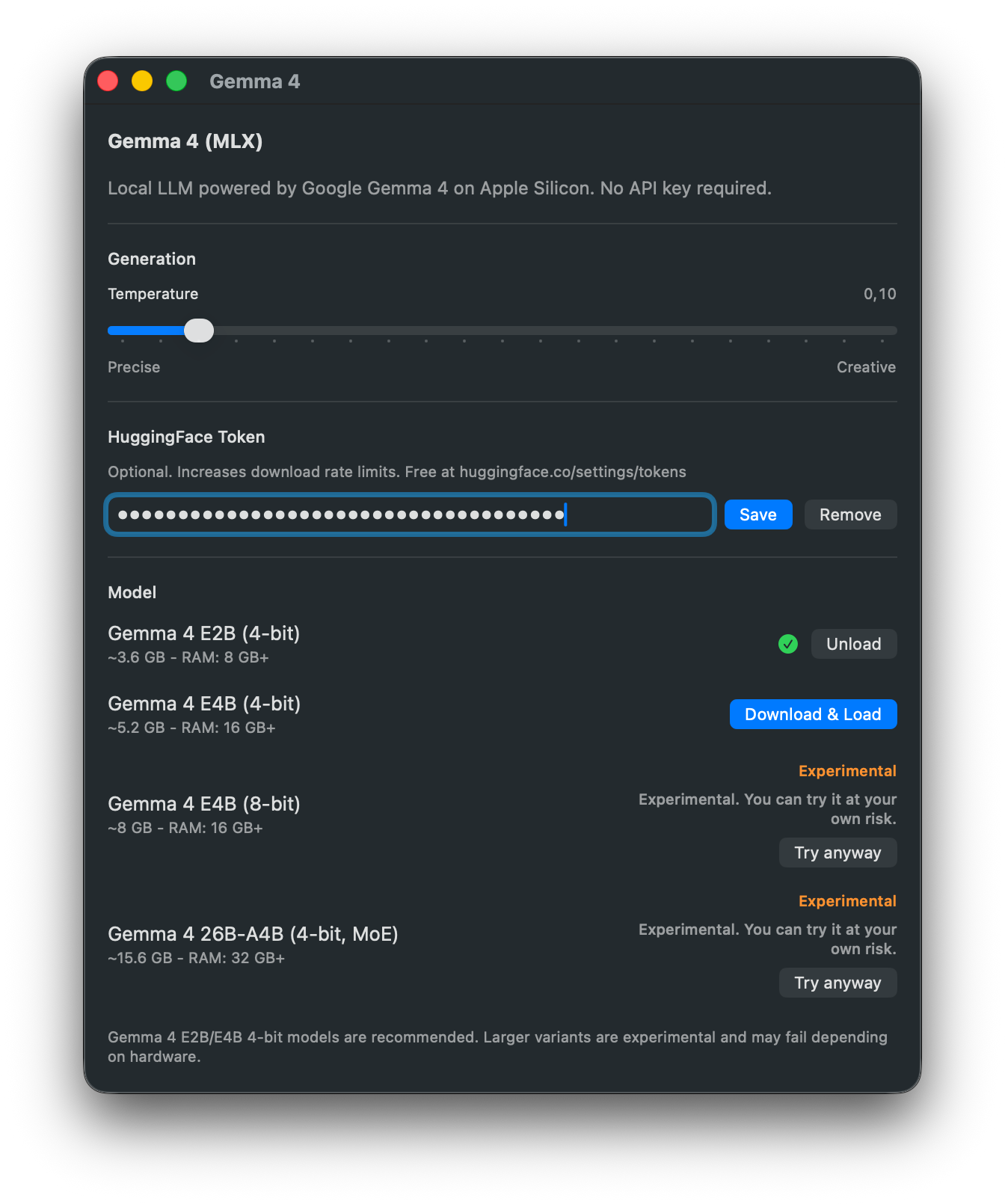
Gemma 4 brings Google’s open-weight Gemma family to TypeWhisper for fully local prompt processing on Apple Silicon. Everything runs on your Mac via MLX, so you can use rewrites, summaries, and custom prompt workflows without sending text to the cloud. In the current verified release path, TypeWhisper officially recommends the dense Gemma 4 E2B (4-bit) and Gemma 4 E4B (4-bit) variants. Larger variants remain visible in the UI, but they are still experimental and may fail depending on hardware or runtime support.
Features
Fully local on-device prompt processing via MLX
Generation temperature slider for more precise or more creative outputs
Optional HuggingFace token for higher download rate limits
HuggingFace token validation before it is saved
Download, load, cancel, and unload controls for local models
Experimental model variants stay visible with explicit warnings
No API key required for the core local workflow
Available Models
Model
Download Size
Recommended RAM
Status
Gemma 4 E2B (4-bit)
~3.6 GB
8 GB+
Supported
Gemma 4 E4B (4-bit)
~5.2 GB
16 GB+
Supported
Gemma 4 E4B (8-bit)
~8 GB
16 GB+
Experimental
Gemma 4 26B-A4B (4-bit, MoE)
~15.6 GB
32 GB+
Experimental
Configuration
Generation Temperature - Adjust the output style between more precise and more creative responses.
HuggingFace Token - Optional. Increases download rate limits and is validated before saving. You can create one at huggingface.co/settings/tokens.
Model - Choose which Gemma 4 variant to download and load. The 4-bit E2B and E4B models are the current recommended path.
Setup
Open TypeWhisper > Settings > Integrations.
Find the Gemma 4 plugin and open its configuration.
Optionally paste a HuggingFace token and save it after validation.
Pick one of the recommended 4-bit models, then click Download & Load.
After the model is loaded, select Gemma 4 (MLX) as the LLM provider in your prompt workflow.
Notes
The currently recommended models are Gemma 4 E2B (4-bit) and Gemma 4 E4B (4-bit).
Larger variants are still experimental and may fail depending on hardware or the current app build.
A HuggingFace token is optional, but it can make downloads more reliable by increasing rate limits.